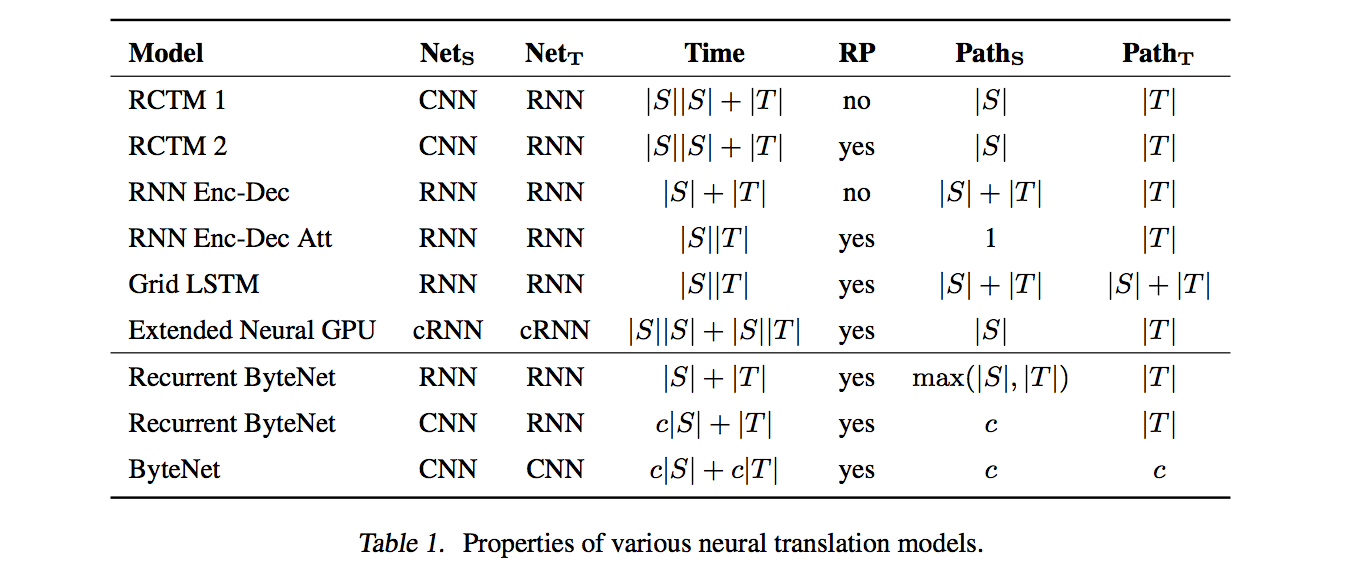
ByteNet 可用于字符级的机器翻译模型并且有着很好的表现,它的特点在于可以在线性时间 (linear time) 完成翻译而且能够处理长距离依赖。它也采用编码器-解码器架构,并且编码器和解码器都由CNN组成。
ByteNet 之所以有上述的这些特性,是因为使用了如下一些技术:
- Dynamic Unfolding
- 解决了生成不同长度翻译的问题
- Dilated Convolution
- 缩短了依赖传播的距离
- Masked 1D Convolution
- 保证训练时只用过去的信息生成当前字符
- Residual Blocks
- 解决梯度消失问题
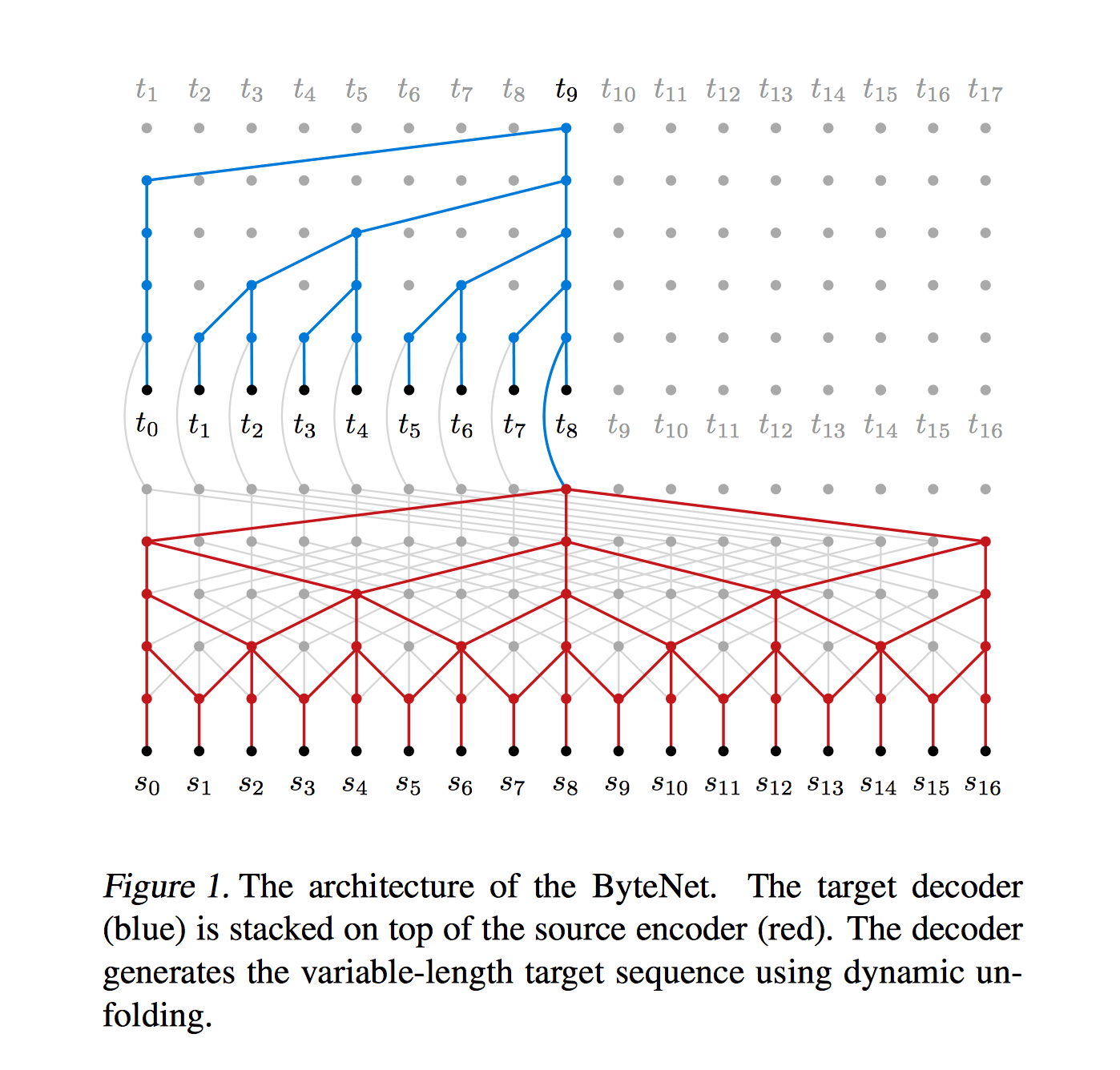
Dynamic Unfolding
Encoder 的输出的句子编码的长度固定为 \(|\hat{t}|\) (不够会补零),是目标句子长度 \(|t|\) 的上界,可以通过下式得到: \[ |\hat{t}| = a|s| + b \] 其中,\(|s|\) 表示源句子长度,通过选择适当的参数 \(a\) 和 \(b\),使得 \(|\hat{t}|\) 基本都大于实际长度 \(|t|\),并且没有太多冗余。
在每一步,decoder 根据当前输入字符和句子特征输出下一个字符,直到生成EOS。至于 decoder 怎么接收输入并 conditioned on 编码器的输出,论文在并没有提及,不过从一个开源实现中看出是直接把输入和编码器在对应位置的输出连接起来,如上图所示。
Dilated Convolution
一维离散卷积的定义为: \[ (f*g)[n] = \sum_{m=-\infty}^{\infty}f[m]g[n-m] = \sum_{m=-M}^Mf[n - m]g[m] \] 例:如果 \(f = [0, 1, 2, -1, 1, -3, 0]\), \(g = [1, 0, -1]\),则按照上式,卷积计算如下所示: \[ \begin{array}{lcl} (f*g)[2] & = & f[2]g[0] + f[1]g[1] + f[0]g[2] = -2 \\ (f*g)[3] & = & f[3]g[0] + f[2]g[1] + f[1]g[2] = 2 \\ ...\\ (f*g)[6] & = & f[6]g[0] + f[5]g[1] + f[4]g[2] = 1 \\ \end{array} \] 和 stride = 1 的普通卷积网络计算一致。

Dilated Convolution的定义为: \[ (f*_lg)[n] = \sum_{m=-\infty}^{\infty}f[m]g[n-lm] = \sum_{m=-M}^Mf[n - lm]g[m] \] 其中,\(l\) 为 dilation factor,控制扩张大小,这样 \(l = 2\) 时上面例子中的卷积就变成了: \[ \begin{array}{lcl} (f*_2g)[4] & = & f[4]g[0] + f[2]g[1] + f[0]g[2] \\ (f*_2g)[5] & = & f[5]g[0] + f[3]g[1] + f[1]g[2] \\ (f*_2g)[6] & = & f[6]g[0] + f[4]g[1] + f[2]g[2] \\ \end{array} \] 当 \(l = 3\) 时,相应卷积就为: \[ (f*_3g)[6] = f[6]g[0] + f[3]g[1] + f[0]g[2] \] 这样虽然卷积核都为3,但 receptive field 的大小却大了很多,所以使用 dialted conv 能使 receptive field 的大小呈指数增长,而相应参数却是线性增长的,如下图所示。使用 dilated conv 就可以有效地缩短依赖传播的距离。
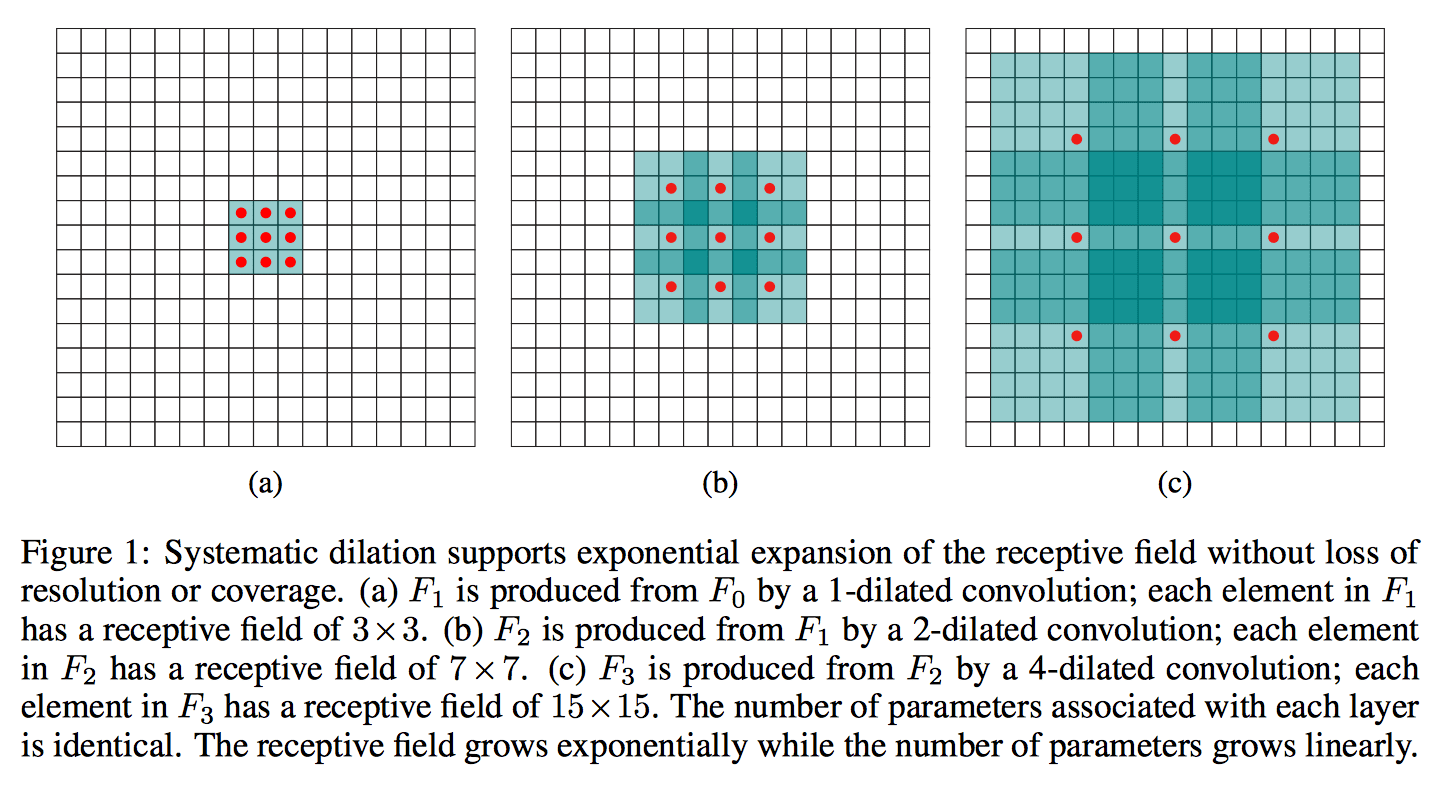
参考:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS
Residual Block
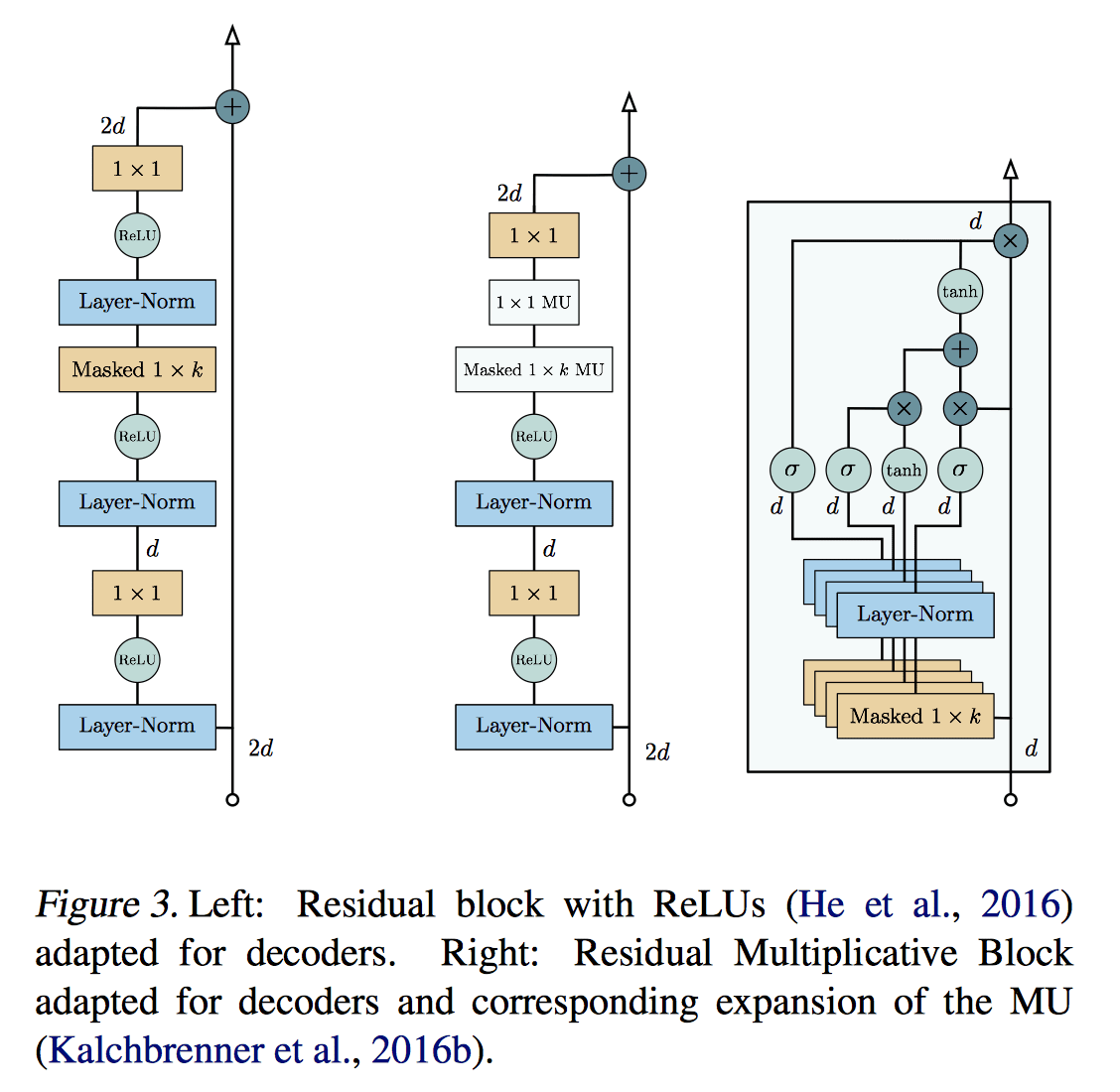
每一层(包括 Encoder 和 Decoder)都封装了一个 residual block(上图),其中每个黄色的格子代表一个卷积层,里面的数字是相应的 filter size。中间的 Masked 1 x K 是这层的主力,其他都是为了使他发挥更大效果的陪衬。
Linear Time